Complément - niveau basique¶
Avertissement¶
Après avoir joué ce cours plusieurs années de suite, l’expérience nous montre qu’il est difficile de trouver le bon moment pour appréhender les expressions régulières.
D’un côté il s’agit de manipulations de chaînes de caractères, mais d’un autre cela nécessite de créer des instances de classes, et donc d’avoir vu la programmation orientée objet. Du coup, les premières années nous les avions étudiées tout à la fin du cours, ce qui avait pu créer une certaine frustration.
C’est pourquoi nous avons décidé à présent de les étudier très tôt, dans cette séquence consacrée aux chaines de caractères. Les étudiants qui seraient décontenancés par ce contenu sont invités à y retourner après la semaine 6, consacrée à la programmation objet.
Il nous semble important de savoir que ces fonctionnalités existent dans le langage, le détail de leur utilisation n’est toutefois pas critique, et on peut parfaitement faire l’impasse sur ce complément en première lecture.
Une expression régulière est un objet mathématique permettant de décrire un ensemble de textes qui possèdent des propriétés communes. Par exemple, s’il vous arrive d’utiliser un terminal, et que vous tapez
$ dir *.txt(ou ls *.txt sur linux ou mac), vous utilisez l’expression régulière *.txt qui désigne tous les fichiers dont le nom se termine par .txt. On dit que l’expression régulière filtre toutes les chaînes qui se terminent par .txt (l’expression anglaise consacrée est le pattern matching).
Attention toutefois, la syntaxe des expressions régulières en Python est plus complexe que les expressions de globbing utilisées dans les lignes de commande, mais permet en contrepartie de faire bien plus de choses. Notamment, le globbing *.txt que nous avons utilisé plus haut deviendrait .*\.txt dans une expression régulière Python (le point . et l’astérisque * ayant des significations particulières et différentes de celles du globbing).
Le langage Perl a été le premier à populariser l’utilisation des expressions régulières en les supportant nativement dans le langage, et non au travers d’une librairie. En python, les expressions régulières sont disponibles de manière plus traditionnelle, via le module re (regular expressions) de la librairie standard.
Le propos de ce complément est de vous en donner une première introduction.
import reSurvol¶
Pour ceux qui ne souhaitent pas approfondir, voici un premier exemple; on cherche à savoir si un objet chaine est ou non de la forme *-*.txt, et si oui, à calculer la partie de la chaine qui remplace le * :
# un objet 'expression régulière' - on dit aussi "pattern"
regexp = r"(.*)-(.*)\.txt"Note: pourquoi le r ?
avec les versions récentes de Python, il est nécessaire ici de préfixer la chaine par r pour créer ce qu’on appelle une raw-string
nous expliquons un peu plus loin la fonction de cette raw-string dans ce contexte, mais en gros, il s’agit simplement de prendre le \ tel quel, sans l’interpréter.
# la chaine de départ
chaine = "abcdef.txt"# la fonction qui calcule si la chaine "matche" le pattern
match = re.match(regexp, chaine)
match is NoneTrueLe fait que l’objet match vaut None indique que la chaine n’est pas de la bonne forme (il manque un - dans le nom); avec une autre chaine par contre :
# la chaine de départ
chaine = "abc-def.txt"The history saving thread hit an unexpected error (OperationalError('attempt to write a readonly database')).History will not be written to the database.
match = re.match(regexp, chaine)
match is NoneFalseIci match est un objet, qui nous permet ensuite d’“extraire” les différentes parties, comme ceci :
match[1]'abc'match[2]'def'Bien sûr on peut faire des choses beaucoup plus élaborées avec re, mais en première lecture cette introduction doit vous suffire pour avoir une idée de ce qu’on peut faire avec les expressions régulières.
Synonymes
Avant d’aller plus loin signalons qu’on utilise indifféremment les termes pour désigner essentiellement la même chose :
expression régulière
en anglais regular expression - d’où le nom du module dans
import reen anglais raccourci regexp, c’est de facto devenu un nom commun
en français on trouve aussi parfois le terme d’expression rationnelle, c’est plus rare et un peu pédant
en anglais on utilise aussi facilement le terme de pattern
qui du coup a été traduit en français par motif; bon ça c’est d’un emploi assez rare.
Après selon les contextes ces termes peuvent être utilisés pour désigner des choses subtilement différentes - par exemple pour distinguer la chaine qui spécifie un pattern de l’objet regexp qui en est déduit; mais à ce stade de la présentation on peut signaler tous ces termes et les assimiler en gros à la même notion.
Complément - niveau intermédiaire¶
Approfondissons à présent:
Dans un terminal, *.txt est une expression régulière très simple. Le module re fournit le moyen de construire des expressions régulières très élaborées et plus puissantes que ce que supporte le terminal. C’est pourquoi la syntaxe des regexps de re est un peu différente. Par exemple comme on vient de le voir, pour filtrer la même famille de chaînes que *-*.txt avec le module re, il nous a fallu écrire l’expression régulière sous une forme légèrement différente.
Je vous conseille d’avoir sous la main la documentation du module re pendant que vous lisez ce complément.
Avertissement¶
Dans ce complément nous serons amenés à utiliser des traits qui dépendent du LOCALE, c’est-à-dire, pour faire simple, de la configuration de l’ordinateur vis-à-vis de la langue.
Tant que vous exécutez ceci dans le notebook sur la plateforme, en principe tout le monde verra exactement la même chose. Par contre, si vous faites tourner le même code sur votre ordinateur, il se peut que vous obteniez des résultats légèrement différents.
Un exemple simple¶
findall¶
On se donne deux exemples de chaînes
sentences = ['Lacus a donec, vitae gravida proin sociis.',
'Neque ipsum! rhoncus cras quam.']On peut chercher tous les mots se terminant par a ou m dans une chaîne avec findall
for sentence in sentences:
print(f"---- dans >{sentence}<")
print(re.findall(r"\w*[am]\W", sentence))---- dans >Lacus a donec, vitae gravida proin sociis.<
['a ', 'gravida ']
---- dans >Neque ipsum! rhoncus cras quam.<
['ipsum!', 'quam.']
Ce code permet de chercher toutes (findall) les occurrences de l’expression régulière, qui ici est définie par la chaine :
r"\w*[am]\W"digression : les raw-strings¶
Pour anticiper un peu, signalons que cette façon de créer un chaine en la préfixant par un r s’appelle une raw-string; l’intérêt c’est de ne pas interpréter les backslashs \
On voit tout de suite l’intérêt sur un exemple :
print("sans raw-string\nun newline")sans raw-string
un newline
print(r"dans\nunraw-string")dans\nunraw-string
Comme vous le voyez dans une chaine “normale” les caractères backslash ont une signification particulière; mais nous ce qu’on veut faire, quand on crée une expression régulière, c’est de laisser les backslashs intacts, car c’est à la couche de regexp de les interpréter.
reprenons¶
Nous verrons tout à l’heure comment fabriquer des expressions régulières plus en détail, mais pour démystifier au moins celle-ci, on a mis bout à bout les morceaux suivants.
\w*: on veut trouver une sous-chaîne qui commence par un nombre quelconque, y compris nul (*) de caractères alphanumériques (\w). Ceci est défini en fonction de votre LOCALE, on y reviendra.[am]: immédiatement après, il nous faut trouver un caratèreaoum.\W: et enfin, il nous faut un caractère qui ne soit pas alphanumérique. Ceci est important puisqu’on cherche les mots qui se terminent par unaou unm, si on ne le mettait pas on obtiendrait ceci
# le \W final est important
# voici ce qu'on obtient si on l'omet
for sentence in sentences:
print(f"---- dans >{sentence}<")
print(re.findall(r"\w*[am]", sentence))
# NB: Comme vous le devinez, ici la notation for ... in ...
# permet de parcourir successivement tous les éléments de la séquence---- dans >Lacus a donec, vitae gravida proin sociis.<
['La', 'a', 'vita', 'gravida']
---- dans >Neque ipsum! rhoncus cras quam.<
['ipsum', 'cra', 'quam']
split¶
Une autre forme simple d’utilisation des regexps est re.split, qui fournit une fonctionnalité voisine de str.split, mais ou les séparateurs sont exprimés comme une expression régulière
for sentence in sentences:
print(f"---- dans >{sentence}<")
print(re.split(r"\W+", sentence))
print()---- dans >Lacus a donec, vitae gravida proin sociis.<
['Lacus', 'a', 'donec', 'vitae', 'gravida', 'proin', 'sociis', '']
---- dans >Neque ipsum! rhoncus cras quam.<
['Neque', 'ipsum', 'rhoncus', 'cras', 'quam', '']
Ici l’expression régulière, qui bien sûr décrit le séparateur, est simplement \W+ c’est-à-dire toute suite d’au moins un caractère non alphanumérique.
Nous avons donc là un moyen simple, et plus puissant que str.split, de couper un texte en mots.
sub¶
Une troisième méthode utilitaire est re.sub qui permet de remplacer les occurrences d’une regexp, comme par exemple
for sentence in sentences:
print(f"---- dans >{sentence}<")
print(re.sub(r"(\w+)", r"X\1Y", sentence))
print()---- dans >Lacus a donec, vitae gravida proin sociis.<
XLacusY XaY XdonecY, XvitaeY XgravidaY XproinY XsociisY.
---- dans >Neque ipsum! rhoncus cras quam.<
XNequeY XipsumY! XrhoncusY XcrasY XquamY.
Ici, l’expression régulière (le premier argument) contient un groupe : on a utilisé des parenthèses autour du \w+. Le second argument est la chaîne de remplacement, dans laquelle on a fait référence au groupe en écrivant \1, qui veut dire tout simplement “le premier groupe”.
Donc au final, l’effet de cet appel est d’entourer toutes les suites de caractères alphanumériques par X et Y.
Pourquoi un raw-string ?¶
En guise de digression, il n’y a aucune obligation à utiliser un raw-string, d’ailleurs on rappelle qu’il n’y a pas de différence de nature entre un raw-string et une chaîne usuelle
raw = r'abc'
regular = 'abc'
# comme on a pris une 'petite' chaîne ce sont les mêmes objets
print(f"both compared with is → {raw is regular}")
# et donc a fortiori
print(f"both compared with == → {raw == regular}")both compared with is → True
both compared with == → True
Il se trouve que le backslash \ à l’intérieur des expressions régulières est d’un usage assez courant - on l’a vu déjà plusieurs fois. C’est pourquoi on utilise fréquemment un raw-string pour décrire une expression régulière. On rappelle que le raw-string désactive l’interprétation des \ à l’intérieur de la chaîne, par exemple, \t est interprété comme un caractère de tabulation dans une chaine usuelle. Sans raw-string, il faut doubler tous les \ pour qu’il n’y ait pas d’interprétation.
Un deuxième exemple¶
Nous allons maintenant voir comment on peut d’abord vérifier si une chaîne est conforme au critère défini par l’expression régulière, mais aussi extraire les morceaux de la chaîne qui correspondent aux différentes parties de l’expression.
Pour cela, supposons qu’on s’intéresse aux chaînes qui comportent 5 parties, une suite de chiffres, une suite de lettres, des chiffres à nouveau, des lettres et enfin de nouveau des chiffres.
Pour cela on considère ces trois chaines en entrée
samples = ['890hj000nnm890', # cette entrée convient
'123abc456def789', # celle-ci aussi
'8090abababab879', # celle-ci non
]match¶
Pour commencer, voyons que l’on peut facilement vérifier si une chaîne vérifie ou non le critère.
regexp1 = "[0-9]+[A-Za-z]+[0-9]+[A-Za-z]+[0-9]+"Si on applique cette expression régulière à toutes nos entrées
for sample in samples:
match = re.match(regexp1, sample)
print(f"{sample:16} → {match}")890hj000nnm890 → <re.Match object; span=(0, 14), match='890hj000nnm890'>
123abc456def789 → <re.Match object; span=(0, 15), match='123abc456def789'>
8090abababab879 → None
Pour rendre ce résultat un peu plus lisible nous nous définissons une petite fonction de confort.
# pour simplement visualiser si on a un match ou pas
def nice(match):
# le retour de re.match est soit None, soit un objet match
return "no" if match is None else "Match!"Avec quoi on peut refaire l’essai sur toutes nos entrées.
# la même chose mais un peu moins encombrant
print(f"REGEXP={regexp1}\n")
for sample in samples:
match = re.match(regexp1, sample)
print(f"{sample:>16} → {nice(match)}")REGEXP=[0-9]+[A-Za-z]+[0-9]+[A-Za-z]+[0-9]+
890hj000nnm890 → Match!
123abc456def789 → Match!
8090abababab879 → no
Ici plutôt que d’utiliser les raccourcis comme \w j’ai préféré écrire explicitement les ensembles de caractères en jeu. De cette façon, on rend son code indépendant du LOCALE si c’est ce qu’on veut faire. Il y a deux morceaux qui interviennent tour à tour :
[0-9]+signifie une suite de au moins un caractère dans l’intervalle[0-9],[A-Za-z]+pour une suite d’au moins un caractère dans l’intervalle[A-Z]ou dans l’intervalle[a-z].
Et comme tout à l’heure on a simplement juxtaposé les morceaux dans le bon ordre pour construire l’expression régulière complète.
Nommer un morceau (un groupe)¶
# on se concentre sur une entrée correcte
haystack = samples[1]
haystack'123abc456def789'Maintenant, on va même pouvoir donner un nom à un morceau de la regexp, ici on désigne par needle le groupe de chiffres du milieu.
# la même regexp, mais on donne un nom au groupe de chiffres central
regexp2 = "[0-9]+[A-Za-z]+(?P<needle>[0-9]+)[A-Za-z]+[0-9]+"Et une fois que c’est fait, on peut demander à l’outil de nous retrouver la partie correspondante dans la chaine initiale:
print(re.match(regexp2, haystack).group('needle'))456
Dans cette expression on a utilisé un groupe nommé (?P<needle>[0-9]+), dans lequel :
les parenthèses définissent un groupe,
?P<needle>spécifie que ce groupe pourra être référencé sous le nomneedle(cette syntaxe très absconse est héritée semble-t-il de perl).
Un troisième exemple¶
Enfin, et c’est un trait qui n’est pas présent dans tous les langages, on peut restreindre un morceau de chaîne à être identique à un groupe déjà vu plus tôt dans la chaîne. Dans l’exemple ci-dessus, on pourrait ajouter comme contrainte que le premier et le dernier groupes de chiffres soient identiques, comme ceci
regexp3 = "(?P<id>[0-9]+)[A-Za-z]+(?P<needle>[0-9]+)[A-Za-z]+(?P=id)"Si bien que maintenant, avec les mêmes entrées que tout à l’heure
print(f"REGEXP={regexp3}\n")
for sample in samples:
match = re.match(regexp3, sample)
print(f"{sample:>16} → {nice(match)}")REGEXP=(?P<id>[0-9]+)[A-Za-z]+(?P<needle>[0-9]+)[A-Za-z]+(?P=id)
890hj000nnm890 → Match!
123abc456def789 → no
8090abababab879 → no
Comme précédemment on a défini le groupe nommé id comme étant la première suite de chiffres.
La nouveauté ici est la contrainte qu’on a imposée sur le dernier groupe avec (?P=id). Comme vous le voyez, on n’obtient un match qu’avec les entrées dans lesquelles le dernier groupe de chiffres est identique au premier.
Comment utiliser la librairie - Compilation des expressions régulières¶
Avant d’apprendre à écrire une expression régulière, disons quelques mots du mode d’emploi de la librairie.
Fonctions de commodité et workflow¶
Comme vous le savez peut-être, une expression régulière décrite sous forme de chaîne, comme par exemple r"\w*[am]\W", peut être traduite dans un automate fini qui permet de faire le filtrage avec une chaîne. C’est ce qui explique le workflow que nous avons résumé dans cette figure.
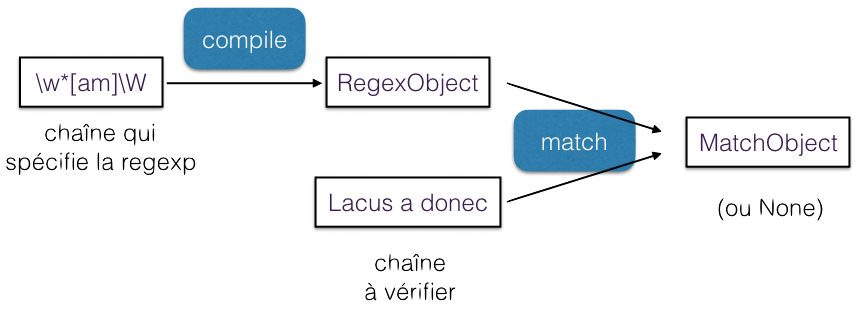
La méthode recommandée pour utiliser la librairie, lorsque vous avez le même pattern à appliquer à un grand nombre de chaînes, est de :
compiler une seule fois votre chaîne en un automate, qui est matérialisé par un objet de la classe
re.RegexObject, en utilisantre.compile,puis d’utiliser directement cet objet autant de fois que vous avez de chaînes.
Nous avons utilisé dans les exemples plus haut (et nous continuerons plus bas pour une meilleure lisibilité) des fonctions de commodité du module, qui sont pratiques, par exemple, pour mettre au point une expression régulière en mode interactif, mais qui ne sont pas forcément adaptées dans tous les cas.
Ces fonctions de commodité fonctionnent toutes sur le même principe :
re.match(regexp, sample) re.compile(regexp).match(sample)
Donc à chaque fois qu’on utilise une fonction de commodité, on recompile la chaîne en automate, ce qui, dès qu’on a plus d’une chaîne à traiter, représente un surcoût.
# au lieu de faire comme ci-dessus:
# imaginez 10**6 chaînes dans samples
for sample in samples:
match = re.match(regexp3, sample)
print(f"{sample:>16} → {nice(match)}") 890hj000nnm890 → Match!
123abc456def789 → no
8090abababab879 → no
# dans du vrai code on fera plutôt:
# on compile la chaîne en automate une seule fois
re_obj3 = re.compile(regexp3)
# ensuite on part directement de l'automate
for sample in samples:
match = re_obj3.match(sample)
print(f"{sample:>16} → {nice(match)}") 890hj000nnm890 → Match!
123abc456def789 → no
8090abababab879 → no
Cette deuxième version ne compile qu’une fois la chaîne en automate, et donc est plus efficace.
Les méthodes sur la classe RegexObject¶
Les objets de la classe RegexObject représentent donc l’automate à état fini qui est le résultat de la compilation de l’expression régulière.
Pour résumer ce qu’on a déjà vu, les méthodes les plus utiles sur un objet RegexObject sont :
matchetsearch, qui cherchent un match soit uniquement au début (match) ou n’importe où dans la chaîne (search),findalletsplitpour chercher toutes les occurrences (findall) ou leur négatif (split),sub(qui aurait pu sans doute s’appelerreplace, mais c’est comme ça) pour remplacer les occurrences de pattern.
Exploiter le résultat¶
Les méthodes disponibles sur la classe re.MatchObject sont documentées en détail ici. On en a déjà rencontré quelques-unes, en voici à nouveau un aperçu rapide.
# exemple
sample = " Isaac Newton, physicist"
match = re.search(r"(\w+) (?P<name>\w+)", sample)re et string pour retrouver les données d’entrée du match.
match.string' Isaac Newton, physicist'match.rere.compile(r'(\w+) (?P<name>\w+)', re.UNICODE)group, groups, groupdict pour retrouver les morceaux de la chaîne d’entrée qui correspondent aux groupes de la regexp. On peut y accéder par rang, ou par nom (comme on l’a vu plus haut avec needle).
match.groups()('Isaac', 'Newton')match.group(1)'Isaac'match.group('name')'Newton'match.group(2)'Newton'match.groupdict(){'name': 'Newton'}Comme on le voit pour l’accès par rang les indices commencent à 1 pour des raisons historiques (on pouvait déjà référencer \1 dans l’éditeur Unix sed à la fin des années 70 !).
On peut aussi accéder au groupe 0 comme étant la partie de la chaîne de départ qui a effectivement été filtrée par l’expression régulière - qui en général est une sous-chaine de la chaîne de départ :
# la sous-chaine filtrée
match.group(0)'Isaac Newton'# la chaine de départ
sample' Isaac Newton, physicist'expand permet de faire une espèce de str.format avec les valeurs des groupes.
match.expand(r"last_name \g<name> first_name \1")'last_name Newton first_name Isaac'span pour connaître les index dans la chaîne d’entrée pour un groupe donné.
# NB: seq[i:j] est une opération de slicing que nous verrons plus tard
# Elle retourne une séquence contenant les éléments de i à j-1 de seq
begin, end = match.span('name')
sample[begin:end]'Newton'Les différents modes (flags)¶
Enfin il faut noter qu’on peut passer à re.compile un certain nombre de flags qui modifient globalement l’interprétation de la chaîne, et qui peuvent rendre service.
Vous trouverez une liste exhaustive de ces flags ici. Ils ont en général un nom long et parlant, et un alias court sur un seul caractère. Les plus utiles sont sans doute :
IGNORECASE(aliasI) pour, eh bien, ne pas faire la différence entre minuscules et majuscules,UNICODE(aliasU) pour rendre les séquences\wet autres basées sur les propriétés des caractères dans la norme Unicode,LOCALE(aliasL) cette fois\wdépend dulocalecourant,MULTILINE(aliasM), etDOTALL(alias S) - pour ces deux derniers flags, voir la discussion à la fin du complément.
Comme c’est souvent le cas, on doit passer à re.compile un ou logique (caractère |) des différents flags que l’on veut utiliser, c’est-à-dire qu’on fera par exemple
regexp = "a*b+"
re_obj = re.compile(regexp, flags=re.IGNORECASE | re.DEBUG)MAX_REPEAT 0 MAXREPEAT
LITERAL 97
MAX_REPEAT 1 MAXREPEAT
LITERAL 98
0. INFO 4 0b0 1 MAXREPEAT (to 5)
5: REPEAT_ONE 6 0 MAXREPEAT (to 12)
9. LITERAL_UNI_IGNORE 0x61 ('a')
11. SUCCESS
12: REPEAT_ONE 6 1 MAXREPEAT (to 19)
16. LITERAL_UNI_IGNORE 0x62 ('b')
18. SUCCESS
19: SUCCESS
# on ignore la casse des caractères
print(regexp, "->", nice(re_obj.match("AabB")))a*b+ -> Match!
Comment construire une expression régulière¶
Nous pouvons à présent voir comment construire une expression régulière, en essayant de rester synthétique (la documentation du module re en donne une version exhaustive).
La brique de base : le caractère¶
Au commencement il faut spécifier des caractères.
un seul caractère:
vous le citez tel quel, en le précédent d’un backslash
\s’il a par ailleurs un sens spécial dans le micro-langage de regexps (comme+,*,[, etc.);
l’attrape-tout (wildcard):
un point
.signifie “n’importe quel caractère”;
un ensemble de caractères avec la notation
[...]qui permet de décrire par exemple:[a1=]un ensemble in extenso, ici un caractère parmia,1, ou=,[a-z]un intervalle de caractères, ici deaàz,[15e-g]un mélange des deux, ici un ensemble qui contiendrait1,5,e,fetg,[^15e-g]une négation, qui a^comme premier caractère dans les[], ici tout sauf l’ensemble précédent;
un ensemble prédéfini de caractères, qui peuvent alors dépendre de l’environnement (UNICODE et LOCALE) avec entre autres les notations:
\wles caractères alphanumériques, et\W(les autres),\sles caractères “blancs” - espace, tabulation, saut de ligne, etc., et\S(les autres),\dpour les chiffres, et\D(les autres).
sample = "abcd"
for regexp in ['abcd', 'ab[cd][cd]', 'ab[a-z]d', r'abc.', r'abc\.']:
match = re.match(regexp, sample)
print(f"{sample} / {regexp:<10s} → {nice(match)}")abcd / abcd → Match!
abcd / ab[cd][cd] → Match!
abcd / ab[a-z]d → Match!
abcd / abc. → Match!
abcd / abc\. → no
Pour ce dernier exemple, comme on a backslashé le . il faut que la chaîne en entrée contienne vraiment un .
print(nice(re.match (r"abc\.", "abc.")))Match!
En série ou en parallèle¶
Si je fais une analogie avec les montages électriques, jusqu’ici on a vu le montage en série, on met des expressions régulières bout à bout qui filtrent (match) la chaine en entrée séquentiellement du début à la fin. On a un peu de marge pour spécifier des alternatives, lorsqu’on fait par exemple
"ab[cd]ef"mais c’est limité à un seul caractère. Si on veut reconnaitre deux mots qui n’ont pas grand-chose à voir comme abc ou def, il faut en quelque sorte mettre deux regexps en parallèle, et c’est ce que permet l’opérateur |
regexp = "abc|def"
for sample in ['abc', 'def', 'aef']:
match = re.match(regexp, sample)
print(f"{sample} / {regexp} → {nice(match)}")abc / abc|def → Match!
def / abc|def → Match!
aef / abc|def → no
Fin(s) de chaîne¶
Selon que vous utilisez match ou search, vous précisez si vous vous intéressez uniquement à un match en début (match) ou n’importe où (search) dans la chaîne.
Mais indépendamment de cela, il peut être intéressant de “coller” l’expression en début ou en fin de ligne, et pour ça il existe des caractères spéciaux:
^lorsqu’il est utilisé comme un caractère (c’est à dire pas en début de[]) signifie un début de chaîne;\Aa le même sens (sauf en mode MULTILINE), et je le recommande de préférence à^qui est déjà pas mal surchargé;$matche une fin de ligne;\Zest voisin de$mais pas tout à fait identique.
Reportez-vous à la documentation pour le détails des différences. Attention aussi à entrer le ^ correctement, il vous faut le caractère ASCII et non un voisin dans la ménagerie Unicode.
sample = 'abcd'
for regexp in [ r'bc', r'\Aabc', r'^abc',
r'\Abc', r'^bc', r'bcd\Z',
r'bcd$', r'bc\Z', r'bc$' ]:
match = re.match(regexp, sample)
search = re.search(regexp, sample)
print(f"{sample} / {regexp:5s} match → {nice(match):6s},"
f" search → {nice(search)}")abcd / bc match → no , search → Match!
abcd / \Aabc match → Match!, search → Match!
abcd / ^abc match → Match!, search → Match!
abcd / \Abc match → no , search → no
abcd / ^bc match → no , search → no
abcd / bcd\Z match → no , search → Match!
abcd / bcd$ match → no , search → Match!
abcd / bc\Z match → no , search → no
abcd / bc$ match → no , search → no
On a en effet bien le pattern bc dans la chaine en entrée, mais il n’est ni au début ni à la fin.
Parenthéser - (grouper)¶
Pour pouvoir faire des montages élaborés, il faut pouvoir parenthéser.
# une parenthése dans une RE
# pour mettre en ligne:
# un début 'a',
# un milieu 'bc' ou 'de'
# et une fin 'f'
regexp = "a(bc|de)f"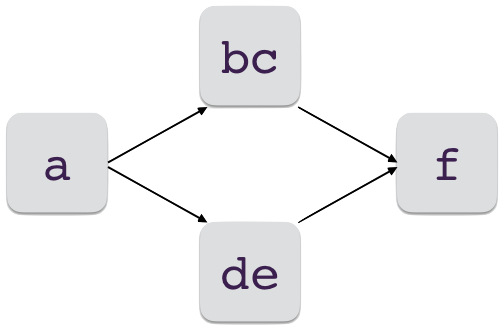
for sample in ['abcf', 'adef', 'abef', 'abf']:
match = re.match(regexp, sample)
print(f"{sample:>4s} → {nice(match)}")abcf → Match!
adef → Match!
abef → no
abf → no
Les parenthèses jouent un rôle additionel de groupe, ce qui signifie qu’on peut retrouver le texte correspondant à l’expression régulière comprise dans les (). Par exemple, pour le premier match
sample = 'abcf'
match = re.match(regexp, sample)
print(f"{sample}, {regexp} → {match.groups()}")abcf, a(bc|de)f → ('bc',)
dans cet exemple, on n’a utilisé qu’un seul groupe (), et le morceau de chaîne qui correspond à ce groupe se trouve donc être le seul groupe retourné par MatchObject.group.
Compter les répétitions¶
Vous disposez des opérateurs suivants :
*l’étoile qui signifie n’importe quel nombre, même nul, d’occurrences - par exemple,(ab)*pour indiquer''ou'ab'ou'abab'ou etc.,+le plus qui signifie au moins une occurrence - e.g.(ab)+pourabouababouabababou etc,?qui indique une option, c’est-à-dire 0 ou 1 occurence - autrement dit(ab)?matche''ouab,{n}pour exactement n occurrences de(ab)- e.g.(ab){3}qui serait exactement équivalent àababab,{m,n}entre m et n fois inclusivement.
# NB: la construction
# [op(elt) for elt in iterable]
# est une compréhension de liste que nous étudierons plus tard.
# Elle retourne une liste contenant les résultats
# de l'opération op sur chaque élément de la liste de départ
samples = [n*'ab' for n in [0, 1, 3, 4]] + ['baba']
for regexp in ['(ab)*', '(ab)+', '(ab){3}', '(ab){3,4}']:
# on ajoute \A \Z pour matcher toute la chaine
line_regexp = r"\A{}\Z".format(regexp)
for sample in samples:
match = re.match(line_regexp, sample)
print(f"{sample:>8s} / {line_regexp:14s} → {nice(match)}") / \A(ab)*\Z → Match!
ab / \A(ab)*\Z → Match!
ababab / \A(ab)*\Z → Match!
abababab / \A(ab)*\Z → Match!
baba / \A(ab)*\Z → no
/ \A(ab)+\Z → no
ab / \A(ab)+\Z → Match!
ababab / \A(ab)+\Z → Match!
abababab / \A(ab)+\Z → Match!
baba / \A(ab)+\Z → no
/ \A(ab){3}\Z → no
ab / \A(ab){3}\Z → no
ababab / \A(ab){3}\Z → Match!
abababab / \A(ab){3}\Z → no
baba / \A(ab){3}\Z → no
/ \A(ab){3,4}\Z → no
ab / \A(ab){3,4}\Z → no
ababab / \A(ab){3,4}\Z → Match!
abababab / \A(ab){3,4}\Z → Match!
baba / \A(ab){3,4}\Z → no
Groupes et contraintes¶
Nous avons déjà vu un exemple de groupe nommé (voir needle plus haut), les opérateurs que l’on peut citer dans cette catégorie sont :
(...)les parenthèses définissent un groupe anonyme,(?P<name>...)définit un groupe nommé,(?:...)permet de mettre des parenthèses mais sans créer un groupe, pour optimiser l’exécution puisqu’on n’a pas besoin de conserver les liens vers la chaîne d’entrée,(?P=name)qui ne matche que si l’on retrouve à cet endroit de l’entrée la même sous-chaîne que celle trouvée pour le groupenameen amont,enfin
(?=...),(?!...)et(?<=...)permettent des contraintes encore plus élaborées, nous vous laissons le soin d’expérimenter avec elles si vous êtes intéressés; sachez toutefois que l’utilisation de telles constructions peut en théorie rendre l’interprétation de votre expression régulière beaucoup moins efficace.
Greedy vs non-greedy¶
Lorsqu’on stipule une répétition un nombre indéfini de fois, il se peut qu’il existe plusieurs façons de filtrer l’entrée avec l’expression régulière. Que ce soit avec *, ou +, ou ?, l’algorithme va toujours essayer de trouver la séquence la plus longue, c’est pourquoi on qualifie l’approche de greedy - quelque chose comme glouton en français.
# un fragment d'HTML
line='<h1>Title</h1>'
# si on cherche un texte quelconque entre crochets
# c'est-à-dire l'expression régulière "<.*>"
re_greedy = '<.*>'
# on obtient ceci
# on rappelle que group(0) montre la partie du fragment
# HTML qui matche l'expression régulière
match = re.match(re_greedy, line)
match.group(0)'<h1>Title</h1>'Ça n’est pas forcément ce qu’on voulait faire, aussi on peut spécifier l’approche inverse, c’est-à-dire de trouver la plus-petite chaîne qui matche, dans une approche dite non-greedy, avec les opérateurs suivants :
*?:*mais non-greedy,+?:+mais non-greedy,??:?mais non-greedy,
# ici on va remplacer * par *? pour rendre l'opérateur * non-greedy
re_non_greedy = re_greedy = '<.*?>'
# mais on continue à cherche un texte entre <> naturellement
# si bien que cette fois, on obtient
match = re.match(re_non_greedy, line)
match.group(0)'<h1>'S’agissant du traitement des fins de ligne¶
Il peut être utile, pour conclure cette présentation, de préciser un peu le comportement de la librairie vis-à-vis des fins de ligne.
Historiquement, les expressions régulières telles qu’on les trouve dans les librairies C, donc dans sed, grep et autre utilitaires Unix, sont associées au modèle mental où on filtre les entrées ligne par ligne.
Le module re en garde des traces, puisque
# un exemple de traitement des 'newlines'
sample = """une entrée
sur
plusieurs
lignes
"""match = re.compile("(.*)").match(sample)
match.groups()('une entrée',)Vous voyez donc que l’attrape-tout '.' en fait n’attrape pas le caractère de fin de ligne \n, puisque si c’était le cas et compte tenu du coté greedy de l’algorithme on devrait voir ici tout le contenu de sample. Il existe un flag re.DOTALL qui permet de faire de . un vrai attrape-tout qui capture aussi les newline
match = re.compile(r"(.*)", flags=re.DOTALL).match(sample)
match.groups()('une entrée\nsur\nplusieurs\nlignes\n',)Cela dit, le caractère newline est par ailleurs considéré comme un caractère comme un autre, on peut le mentionner dans une regexp comme les autres. Voici quelques exemples pour illustrer tout ceci
# (depuis Python 3) sans mettre de flag, \w matche l'Unicode
match = re.compile(r"([\w ]*)").match(sample)
match.groups()('une entrée',)# pour matcher les caractères ASCII avec \w
# il faut mentionner le flag ASCII re.A
match = re.compile(r"([\w ]*)", flags=re.A).match(sample)
match.groups()('une entr',)# si on ajoute \n à la liste des caractères attendus
# on obtient bien tout le contenu initial
match = re.compile(r"([\w \n]*)", flags=re.UNICODE).match(sample)
match.groups()('une entrée\nsur\nplusieurs\nlignes\n',)Conclusion¶
La mise au point d’expressions régulières est certes un peu exigeante, et demande pas mal de pratique, mais permet d’écrire en quelques lignes des fonctionnalités très puissantes, c’est un investissement très rentable :)
Je vous signale enfin l’existence de sites web qui évaluent une expression régulière de manière interactive et qui peuvent rendre la mise au point moins fastidieuse.
Je vous signale notamment https://pythex.org/, il en existe beaucoup d’autres.
Un élève, qui a eu notamment des soucis avec le \w sur pythex.org (dont, on l’a vu, la signification dépend du locale de la machine hôte) recommande pour sa part https://
Ce site est très didactique et lui reconnait les caractères accentués sur un
\wsans rajouter de flag (même si cette option est possible).
Pour en savoir plus¶
Pour ceux qui ont quelques rudiments de la théorie des langages, vous savez qu’on distingue en général
l’analyse lexicale, qui découpe le texte en morceaux (qu’on appelle des tokens),
et l’analyse syntaxique qui décrit pour simplifier à l’extrême l’ordre dans lequel on peut trouver les tokens.
Avec les expression régulières, on adresse le niveau de l’analyse lexicale. Pour l’analyse syntaxique, qui est franchement au delà des objectifs de ce cours, il existe de nombreuses alternatives, parmi lesquelles:
ANTLRqui est un outil écrit en Java mais qui peut générer des parsers en python,...