Ce complément expose quelques bases concernant les caractères accentués, et notamment les précautions à prendre pour pouvoir en insérer dans un programme Python. Nous allons voir que cette question, assez scabreuse, dépasse très largement le cadre de Python.
Complément - niveau basique¶
Un caractère n’est pas un octet¶
Avec Unicode, on a cassé le modèle un caractère == un octet. Aussi en Python 3, lorsqu’il s’agit de manipuler des données provenant de diverses sources de données :
le type
byteest approprié si vous voulez charger en mémoire les données binaires brutes, sous forme d’octets donc ;le type
strest approprié pour représenter une chaîne de caractères - qui, à nouveau ne sont pas forcément des octets ;on passe de l’un à l’autre de ces types par des opérations d’encodage et décodage, comme illustré ci-dessous ;
et pour toutes les opérations d’encodage et décodage, il est nécessaire de connaître l’encodage utilisé.
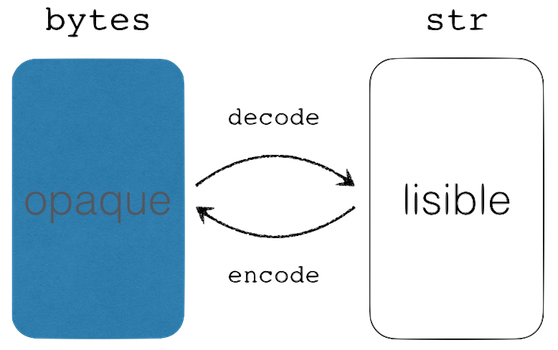
On peut appeler les méthodes encode et decode sans préciser l’encodage (dans ce cas Python choisit l’encodage par défaut sur votre système). Cela dit, il est de loin préférable d’être explicite et de choisir son encodage. En cas de doute, il est recommandé de spécifier explicitement utf-8, qui se généralise au détriment d’encodages anciens comme cp1252 (Windows) et iso8859-*, que de laisser le système hôte choisir pour vous.
Utilisation des accents et autres cédilles¶
Python 3 supporte Unicode par défaut. Vous pouvez donc, maintenant, utiliser sans aucun risque des accents ou des cédilles dans vos chaînes de caractères. Il faut cependant faire attention à deux choses :
Python supporte Unicode, donc tous les caractères du monde, mais les ordinateurs n’ont pas forcément les polices de caractères nécessaires pour afficher ces caractères ;
Python permet d’utiliser des caractères Unicode pour les noms de variables, mais nous vous recommandons dans toute la mesure du possible d’écrire votre code en anglais, comme c’est le cas pour la quasi-totalité du code que vous serez amenés à utiliser sous forme de bibliothèques. Ceci est particulièrement important pour les noms de lignes et de colonnes dans un dataset afin de faciliter les transferts entre logiciels, la majorité des logiciels n’acceptant pas les accents et cédilles dans les noms de variables.
Ainsi, il faut bien distinguer les chaînes de caractères qui doivent par nature être adaptées au langage des utilisateurs du programme, et le code source qui lui est destiné aux programmeurs et qui doit donc éviter d’utiliser autre chose que de l’anglais.
Complément - niveau intermédiaire¶
Où peut-on mettre des accents ?¶
Cela étant dit, si vous devez vraiment mettre des accents dans vos sources, voici ce qu’il faut savoir.
Noms de variables¶
S’il n’était pas possible en Python 2 d’utiliser un caractère accentué dans un nom de variable (ou d’un identificateur au sens large), cela est à présent permis en Python 3 :
# pas recommandé, mais autorisé par le langage
nb_élèves = 12On peut même utiliser des symboles, comme par exemple
from math import cos, pi as 𝞟
θ = 𝞟 / 4
cos(θ)0.7071067811865476Je vous recommande toutefois de ne pas utiliser cette possibilité, si vous n’êtes pas extrêmement familier avec les caractères Unicode.
Enfin, pour être exhaustif, sachez que seule une partie des caractères Unicode sont autorisés dans ce cadre, c’est heureux parce que les caractères comme, par exemple, l’espace non-sécable pourraient, s’ils étaient autorisés, être la cause de milliers d’heures de debugging à frustration garantie :)
Pour les curieux, vous pouvez en savoir plus à cet endroit de la documentation officielle (en anglais).
Chaînes de caractères¶
Vous pouvez naturellement mettre des accents dans les chaînes de caractères. Cela dit, les données manipulées par un programme proviennent pour l’essentiel de sources externes, comme une base de données ou un formulaire Web, et donc le plus souvent pas directement du code source. Les chaînes de caractères présentes dans du vrai code sont bien souvent limitées à des messages de logging, et le plus souvent d’ailleurs en anglais, donc sans accent.
Lorsque votre programme doit interagir avec les utilisateurs et qu’il doit donc parler leur langue, c’est une bonne pratique de créer un fichier spécifique, que l’on appelle fichier de ressources, qui contient toutes les chaînes de caractères spécifiques à une langue. Ainsi, la traduction de votre programme consistera à simplement traduire ce fichier de ressources.
message = "on peut mettre un caractère accentué dans une chaîne"Commentaires¶
Enfin on peut aussi bien sûr mettre dans les commentaires n’importe quel caractère Unicode, et donc notamment des caractères accentués si on choisit malgré tout d’écrire le code en français.
# on peut mettre un caractère accentué dans un commentaire
# ainsi que cos(Θ) ➨ ∀x ∈ ∫f(t)dt∰ vous voyez l'idée généraleQu’est-ce qu’un encodage ?¶
Comme vous le savez, la mémoire - ou le disque - d’un ordinateur ne permet que de stocker des représentations binaires. Il n’y a donc pas de façon “naturelle” de représenter un caractère comme ‘A’, un guillemet ou un point-virgule.
On utilise pour cela un encodage, par exemple le code US-ASCII stipule, pour faire simple, qu’un ‘A’ est représenté par l’octet 65 qui s’écrit en binaire 01000001. Il se trouve qu’il existe plusieurs encodages, bien sûr incompatibles, selon les systèmes et les langues. Vous trouverez plus de détails ci-dessous.
Le point important est que pour pouvoir ouvrir un fichier “proprement”, il faut bien entendu disposer du contenu du fichier, mais il faut aussi connaître l’encodage qui a été utilisé pour l’écrire.
Précautions à prendre pour l’encodage de votre code source¶
L’encodage ne concerne pas simplement les objets chaîne de caractères, mais également votre code source. Python 3 considère que votre code source utilise par défaut l’encodage UTF-8. Nous vous conseillons de conserver cet encodage qui est celui qui vous offrira le plus de flexibilité.
Vous pouvez malgré tout changer l’encodage de votre code source en faisant figurer dans vos fichiers, en première ou deuxième ligne, une déclaration comme ceci :
# -*- coding: <nom_de_l_encodage> -*-ou plus simplement, comme ceci :
# coding: <nom_de_l_encodage>Notons que la première option est également interprétée par l’éditeur de texte Emacs pour utiliser le même encodage. En dehors de l’utilisation d’Emacs, la deuxième option, plus simple et donc plus pythonique, est à préférer.
Le nom UTF-8 fait référence à Unicode (ou pour être précis, à l’encodage le plus répandu parmi ceux qui sont définis dans la norme Unicode, comme nous le verrons plus bas). Sur certains systèmes plus anciens vous pourrez être amenés à utiliser un autre encodage. Pour déterminer la valeur à utiliser dans votre cas précis vous pouvez faire dans l’interpréteur interactif :
# ceci doit être exécuté sur votre machine
import sys
print(sys.getdefaultencoding())Par exemple avec d’anciennes versions de Windows (en principe de plus en plus rares) vous pouvez être amenés à écrire :
# coding: cp1252La syntaxe de la ligne coding est précisée dans cette documentation et dans le PEP 263.
Le grand malentendu¶
Si je vous envoie un fichier contenant du français encodé avec, disons, ISO/IEC 8859-15 - a.k.a. Latin-9; vous pouvez voir dans la table qu’un caractère ‘€’ va être matérialisé dans mon fichier par un octet ‘0xA4’, soit 164.
Imaginez maintenant que vous essayez d’ouvrir ce même fichier depuis un vieil ordinateur Windows configuré pour le français. Si on ne lui donne aucune indication sur l’encodage, le programme qui va lire ce fichier sur Windows va utiliser l’encodage par défaut du système, c’est-à-dire CP1252. Comme vous le voyez dans cette table, l’octet ‘0xA4’ correspond au caractère ¤ et c’est ça que vous allez voir à la place de €.
Contrairement à ce qu’on pourrait espérer, ce type de problème ne peut pas se régler en ajoutant une balise # coding: <nom_de_l_encodage>, qui n’agit que sur l’encodage utilisé pour lire le fichier source en question (celui qui contient la balise).
Pour régler correctement ce type de problème, il vous faut préciser explicitement l’encodage à utiliser pour décoder le fichier. Et donc avoir un moyen fiable de déterminer cet encodage; ce qui n’est pas toujours aisé d’ailleurs, mais c’est une autre discussion malheureusement.
Ce qui signifie que pour être totalement propre, il faut pouvoir préciser explicitement le paramètre encoding à l’appel de toutes les méthodes qui sont susceptibles d’en avoir besoin.
Pourquoi ça marche en local ?¶
Lorsque le producteur (le programme qui écrit le fichier) et le consommateur (le programme qui le lit) tournent dans le même ordinateur, tout fonctionne bien - en général - parce que les deux programmes se ramènent à l’encodage défini comme l’encodage par défaut.
Il y a toutefois une limite, si vous utilisez un Linux configuré de manière minimale, il se peut qu’il utilise par défaut l’encodage US-ASCII - voir plus bas - qui étant très ancien ne “connaît” pas un simple é, ni a fortiori €. Pour écrire du français, il faut donc au minimum que l’encodage par défaut de votre ordinateur contienne les caractères français, comme par exemple :
ISO 8859-1(Latin-1)ISO 8859-15(Latin-9)UTF-8CP1252
À nouveau dans cette liste, il faut clairement préférer UTF-8 lorsque c’est possible.
Un peu d’histoire sur les encodages¶
Le code US-ASCII¶
Jusque dans les années 1980, les ordinateurs ne parlaient pour l’essentiel que l’anglais. La première vague de standardisation avait créé l’encodage dit ASCII, ou encore US-ASCII voir par exemple ici, ou encore en version longue ici.
Le code US-ASCII s’étend sur 128 valeurs, soit 7 bits, mais est le plus souvent implémenté sur un octet pour préserver l’alignement, le dernier bit pouvant être utilisé par exemple pour ajouter un code correcteur d’erreur - ce qui à l’époque des modems n’était pas superflu. Bref, la pratique courante était alors de manipuler une chaîne de caractères comme un tableau d’octets.
Les encodages ISO8859-* (Latin*)¶
Dans les années 1990, pour satisfaire les besoins des pays européens, ont été définis plusieurs encodages alternatifs, connus sous le nom de ISO/IEC 8859-*, nommés aussi Latin-*. Idéalement, on aurait pu et certainement dû définir un seul encodage pour représenter tous les nouveaux caractères, mais entre toutes les langues européennes, le nombre de caractères à ajouter était substantiel, et cet encodage unifié aurait largement dépassé 256 caractères différents, il n’aurait donc pas été possible de tout faire tenir sur un octet.
On a préféré préserver la “bonne propriété” du modèle un caractère == un octet, ceci afin de préserver le code existant qui aurait sinon dû être retouché ou réécrit.
Dès lors il n’y avait pas d’autre choix que de définir plusieurs encodages distincts, par exemple, pour le français on a utilisé à l’époque ISO/IEC 8859-1 (Latin-1), pour le russe ISO/IEC 5589-5 (Latin/Cyrillic).
À ce stade, le ver était dans le fruit. Depuis cette époque pour ouvrir un fichier il faut connaître son encodage.
Unicode¶
Lorsque l’on a ensuite cherché à manipuler aussi les langues asiatiques, il a de toute façon fallu définir de nouveaux encodages beaucoup plus larges. C’est ce qui a été fait par le standard Unicode qui définit 3 nouveaux encodages :
UTF-8: un encodage à taille variable, à base d’octets, qui maximise la compatibilité avec US-ASCII ;UTF-16: un encodage à taille variable, à base de mots de 16 bits ;UTF-32: un encodage à taille fixe, à base de mots de 32 bits ;
Ces 3 standards couvrent le même jeu de caractères (113 021 tout de même dans la dernière version). Parmi ceux-ci le plus utilisé est certainement UTF-8. Un texte ne contenant que des caractères du code US-ASCII initial peut être lu avec l’encodage UTF-8.
Pour être enfin tout à fait exhaustif, si on sait qu’un fichier est au format Unicode, on peut déterminer quel est l’encodage qu’il utilise, en se basant sur les 4 premiers octets du document. Ainsi dans ce cas particulier (lorsqu’on est sûr qu’un document utilise un des trois encodages Unicode) il n’est plus nécessaire de connaître son encodage de manière “externe”.